We hear about correlations every day. Various health outcomes are
correlated with socioeconomic
status. Iodine
supplementation in infants is correlated with higher
IQ. Models are
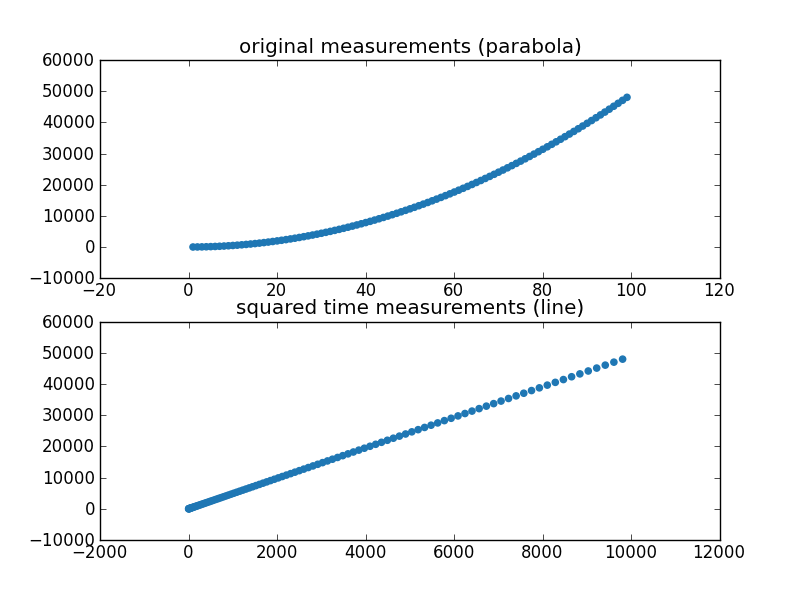
everywhere as well. An object falling for t seconds moves .5gt^2
meters. You can calculate correlation and build approximate models
using several techniques, but the simplest and most popular
technique by far is linear regression . Let's see how it
works!
County Health Rankings
For our examples, we'll use the County Health
Rankings. Specifically,
we'll be looking at two datasets in this example: Years of
Potential Life
Lost
and Additional
Measures.
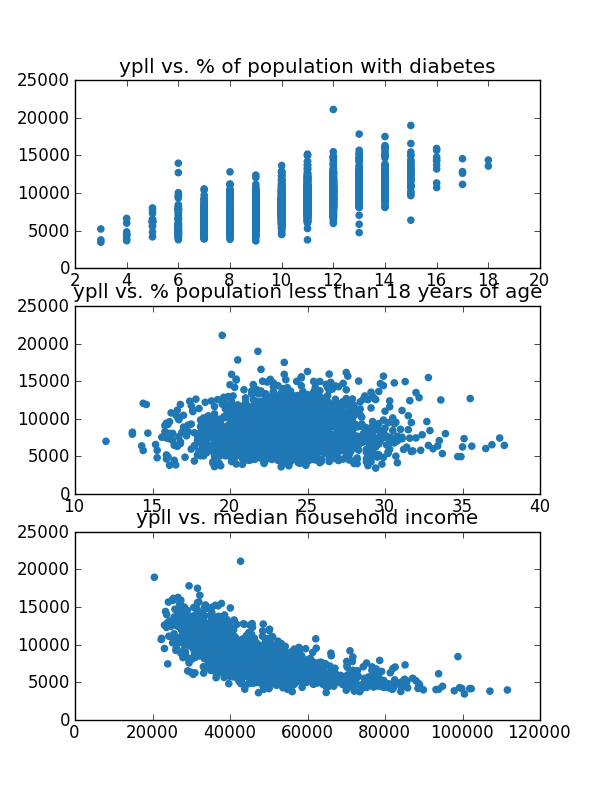
Years of potential life lost (YPLL) is an early mortality measure. It
measures, across 100,000 people, the total number of
years below the age of 75 that a 100,000-person group loses. For
example, if a person dies at age 73, they contribute 2 years to this
sum. If they die at age 77, they contribute 0 years to the sum.
The YPLL for each 100,000 people, averaged across counties in the
United States is between 8000 and 9000 depending on the year. The
file ypll.csv contains per-county YPLLs for the United States in
2011.
The additional measures (found in additional_measures_cleaned.csv)
contains all sorts of fun measures per county, ranging from the
percentage of people in the county with Diabetes to the population
of the county.
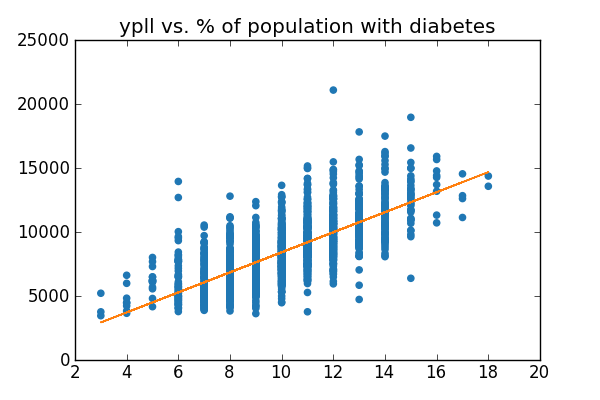
We're going to see which of the additional measures correlate
strongly with our mortality measure, and build predictive models for
county mortality rates given these additional measures.
Loading the Rankings
The two .csv files we've given you (ypll.csv and
additional_measures_cleaned.csv) went through quote a bit of
scrubbing already. You can read our notes on the
process
if you're interested.
We need to perform some data cleaning and filtering when loading the
data. There is a column called "Unreliable" that will be marked if
we shouldn't trust the YPLL data. We want to ignore those. Also,
some of the rows won't contain data for some of the additional
measures. For example, Yakutat, Alaska doesn't have a value for %
child illiteracy. We want to skip those rows. Finally, there is a
row per state that summarizes the state's statistics. It has an
empty value for the "county" column and we want to
ignore those rows since we are doing a county-by-county
analysis. Here's a function, read_csv, that will read the desired
columns from one of the csv files.
{kind=link}